Prompt Engineering Basics: A Guide to Working with AI for Customer Teams

Businesses increasingly rely on LLM-powered AI tools like ChatGPT, Claude, and Google Gemini, but they often struggle to get the most out of their investments. While many people are familiar with the process of prompting these tools with data and instructions, it still takes a lot of effort and finesse to produce quality results.
Enter: prompt engineering — the process of developing prompts to extract the best possible results from AI systems. This guide introduces you to the concept of prompt engineering and shows how to go about the trial and error process of building effective AI prompts for sales, support, and other business functions.
What is prompt engineering?
At their simplest, LLMs work through call and response: You give the model some text written in natural language (i.e., a “prompt”) and you get some text back. This text includes instructions and data for the LLM to use in its response.
But the way you put together a prompt can greatly influence your results. Prompt engineering is the process of optimizing your results by systematically adjusting your prompts.
While prompt engineering, it helps to remember an important point: LLMs don't inherently know what a user wants. Rather than passively accepting whatever response an LLM generates, prompt engineers iteratively modify their prompts' structure and specificity to steer the AI towards outputs that better match their intent. The practice is a great way to get more value from your AI tools, as it doesn't require programming knowledge and anyone working with AI systems can do it.
As you work through the steps of prompt engineering, it also helps to treat your AI model (LLM) and use case as an integrated package. Models are each trained and structured differently, so an approach to prompting that works well for one model (say, ChatGPT) may not work as well with another model (say, Llama 4). Think about it like this: You can ask 10 different artists to paint a “serene landscape” and you’ll get 10 very different paintings — but one of them will most closely match what you want. The same goes for prompts and the models that work with them. You can’t simply follow a plug-and-play approach, but instead need to tailor prompts to match both a specific AI model and its intended use case.
Prompt engineering vs. LLM fine-tuning
Prompt engineering and fine-tuning are both used to improve outputs from an LLM, but they are two different processes that occur at different stages of AI development and workflows.
Generally, LLMs are trained and then remain static until they are re-trained or fine-tuned to update their data and behavior. When you prompt an AI, the model itself isn't modified by the prompting process; it only returns a response based on its fixed training data. Prompt engineering tries to optimize the instructions given to an LLM and guide its decision making to generate a better response to user queries. Fine-tuning an LLM, on the other hand, takes an existing model and adapts it to a more specific goal before people start using it, changing what the AI already knows but not the decision making.
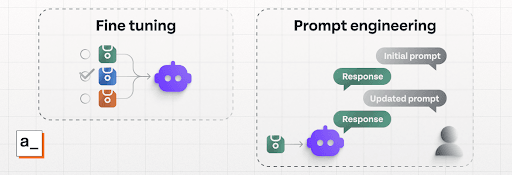
Fine-tuning is a highly effective method for getting more specific, accurate responses out of an LLM. It is also very time-consuming and expensive. While prompt engineering is not the same thing as fine-tuning, it can be a cost-effective alternative to it: by crafting prompts that work to an LLM’s existing strengths and providing additional data and context in a targeted manner, users can greatly improve the outcomes of their AI tools — even if they don’t have the programming knowledge or experience in training LLMs.
What are the basic elements of prompt engineering?
There are several core concepts and processes that result in effective prompt engineering:
System prompts: Not all parts of the prompt that the LLM receives are visible to users. ”System prompts” are prepended to user input to provide additional instructions, restraints, or context. For example, a system prompt could invisibly add a persona (described below) to an AI chat, or it could supply a list of topics that the LLM should not include in its responses.
Prompt personas: By developing a role for your AI (”role” as in “role playing”), you can provide additional context and encourage more specific responses. For example, if an LLM is tasked with interacting with customers, instructing it to adopt a “friendly customer service” persona as part of its prompt will encourage it to respond using more positive and helpful language.
Iteration: The process of refining and testing prompts until they consistently produce the best results usually involves small tweaks — like changing wording, reordering instructions, or adding examples. Even minor changes can drastically improve AI outputs, which means incremental updates are key to prompt engineering.
A recorded history of prompts and responses: Tracking and recording your interaction with an LLM as you iterate your prompts helps mitigate the black-box nature of AI technologies, helping you identify exactly which prompts get the best results, and which tweaks make the greatest impact (which will help you get more efficient at iterating on future prompts).
Why does prompt engineering matter for your business?
Prompt engineering offers an immediate improvement to the ROI of your AI toolchain. It’s also a way to enhance your customers' experience and stay ahead of your competitors without extra costs or technical skills. As it occurs at the end-user level, your teams can develop and optimize unique prompts for each department and even for individual use cases to deliver personalized experiences at scale — without any programming knowledge.
Well-crafted prompts improve the accuracy, relevance, and efficiency of LLM responses, reducing the need for manual edits and corrections. Prompt engineering also provides a cost-effective alternative to using larger AI models, which may be impractical for teams working at a smaller scale. It is proven to give smaller LLMs (which require far fewer resources) the potential to match the performance of much larger models on specialized tasks. Even if a company has more resources at their disposal, prompt engineering fully taps into a model’s capabilities.
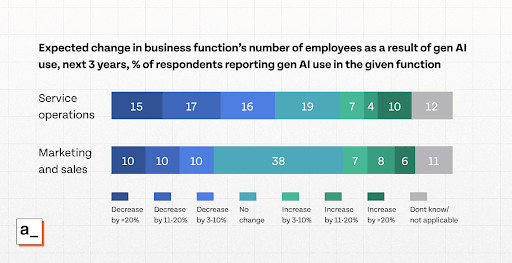
Caption: AI adoption is expected to reduce the number of employees in marketing, sales, and service operations over the next three years (Source: McKinsey & Company '”The state of AI”' survey 2025).
Another risk when dealing with LLMs is that they are prone to hallucinations, generating factually incorrect responses. Prompting can tackle this by asking for confidence scores or by breaking down LLMs decision making. Implementing techniques like chain-of-thought reasoning can make the AI’s decisions more transparent and reduce the chance of an AI misfire causing problems for your business.
LLM’s shouldn't be treated as deterministic systems, as you can’t expect the same prompt to behave similarly with different models (or even the same model in different settings). The best practice is to test prompts yourself repeatedly and assess the results: this involves a certain level of trial and error, and it requires domain knowledge of the topic and task at hand to verify the accuracy of results and steer prompts in the right direction.
Prompt engineering examples for customer sales and support teams
Prompt engineering is not an exact science — there’s no right way to do it — but it should be methodical, and it should be based on the experience and observations of each team so that AI workflows can be iteratively improved for different scenarios. For example:
Sales teams can iterate on a prompt to generate personalized outreach emails with just the right level of persuasion.

Support teams can extract concise ticket summaries that remove superfluous information so that agents can assess support requests faster, with the option of using a suggested pre-written reply.

Customer success teams can automate renewal reminders and plan out engagement strategies by supplying customer information in the prompt to personalize them.

Let’s take the example of prompt engineering for the support team to showcase how you can set up an entire prompt iteration pipeline.
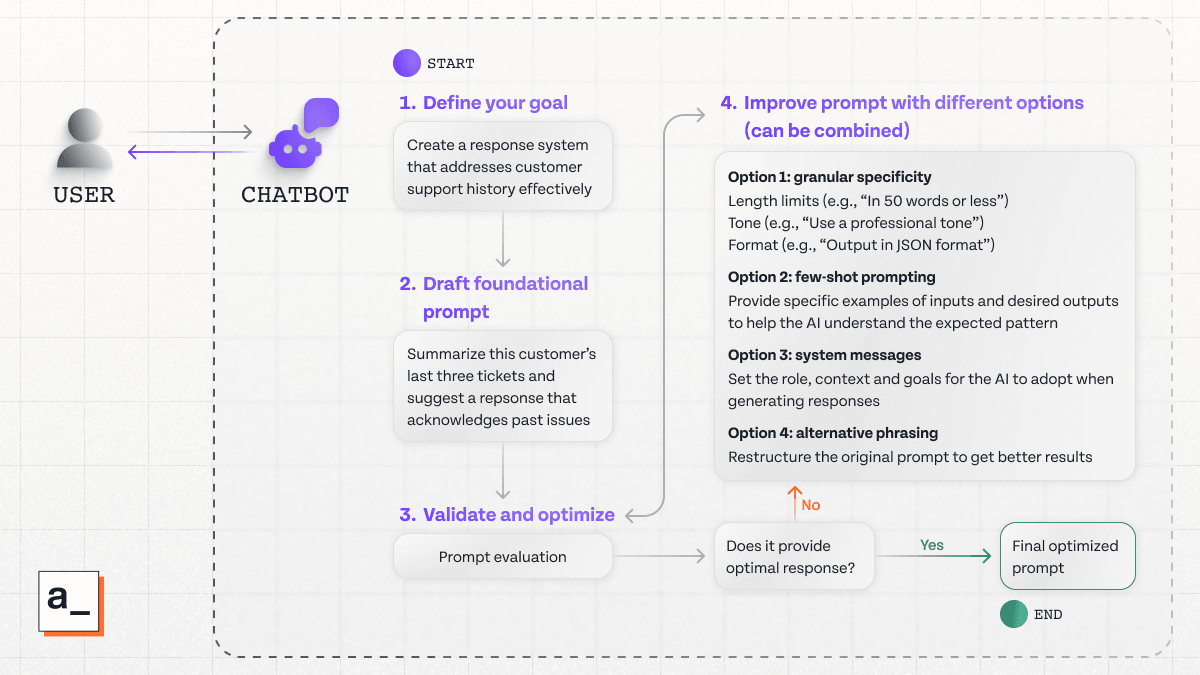
How to test and improve the effectiveness of a prompt
Evaluating your LLM prompts is crucial to make sure you’re steering your LLMs towards better responses, not away from them. The most effective way to do this is by directly comparing how the AI responds to different prompts based on the unique metrics that indicate success for a given task.
The following criteria can help you define your evaluation objective before you prompt the model.
Relevance measures how well the LLM response addresses the core task given by the user.
Accuracy is how factually correct the response is. As LLMs are prone to hallucinations, it's important to ensure your prompts are returning verifiable outputs.
Tone measures if the response matches the communication style expected by the user.
You can then apply testing techniques like A/B testing to compare different prompt versions on the same model and task. To capture edge cases where a prompt may be performing poorly, stress testing can help further lock in what a “good” response looks like, and develop prompts that are highly likely to result in such responses. By testing on different metrics, you can iteratively refine your prompts and get better responses from your LLM.
Potential pitfalls of prompting and how to avoid them
The “separation of concerns” concept from software development also applies to effective AI prompting. Adding too many instructions to a single prompt may confuse the model and lead to decreased performance. To avoid this, you should keep prompts focused on a specific task by ensuring that you:
Be clear: Avoid ambiguity and be explicit about what you need.
Provide focused context: Providing necessary background to the AI about the task helps it understand requests in the right context. Overloading the prompt with context (like many examples) can confuse the model from its core task. Few-shot prompting offers the perfect balance of context and clarity with just enough examples to guide the AI’s output without excessive information.
Add constraints: Scope the functionalities you are trying to build and create a list of do’s and don’ts based on the LLM’s responsibilities. Define formats, word limits, or response structures to get structured outputs. This also makes evaluating prompts easier.
Leverage your domain knowledge: The prompt engineer needs some prior knowledge to know what a “correct” response looks like to catch when LLMs hallucinate or are factually incorrect.
Break things down: For more complex responses, you could consider individual prompts for each component, and then a final prompt for the LLM to merge the different responses.
How prompt engineering is set to change in 2025
The best way to keep up with the current technological landscape, where more powerful LLMs are being released daily, is by doing research on the model and specific use case you’re choosing it for. Better prompts will help you leverage the tools in your arsenal and enable smaller models to perform toe-to-toe with bigger models.
AI tools are quickly becoming better at understanding user intent, reducing the need for ultra-precise prompts. With new reasoning models like DeepSeek R1 and OpenAI o1 continuing to change prompt engineering best practices, traditional methods may provide worse results on these models. This makes it vital to keep track of your prompts and their effectiveness with different models and versions.
Engineers and developers are enhancing AI’s capabilities by combining prompt engineering with function calling or retrieval augmented generation (RAG).
Function calling lets you directly interact with connected third-party systems, triggering normal processes in databases and SaaS tools using natural language.
Retrieval augmented generation (RAG) lets you access different data sources at query time and augments the user query with the retrieved data for better results, giving the LLM relevant and up-to-date information without having to retrain it. This reduces hallucinations and maintains the security of internal company documents by only pulling relevant data.
However, expect to see more businesses integrate prompt engineering into workflows and automate tasks without a heavy reliance on technical expertise. This democratization of AI to people from non-tech backgrounds has become more feasible due to the rise of no-code platforms and embedded AI copilots, which enable employees across an organization to develop and expand AI technologies.
Building smarter prompt-powered apps with Appsmith
Prompt engineering is just one part of building reliable AI workflows. Businesses also need the ability to integrate prompts with live data, tailor AI behavior to specific use cases, and safely deploy those workflows across sales, support, and success teams.
We’re building the next generation of AI-powered apps at Appsmith — focused on giving teams full control over how AI integrates with their tools, workflows, and customer data.
These new capabilities will make it easier to design prompt pipelines, connect them to your internal systems, and deploy them across your business.
👉 Want early access? Join the waitlist: www.appsmith.com


