LLM Hallucination: How to Reliably De-hallucinate AI Agents

Have you ever asked a chatbot a question and had it confidently reply with a completely incorrect answer? This is a common occurrence and a problem inherent in the technology. If you’ve considered adopting AI solutions for your business, you should be aware of these “hallucinations” and how to mitigate them so you don't have to second-guess every AI response.
This article explains what causes AI hallucinations and shows you how you can keep them in check to get the most value out of your AI investments, protect your data, and safeguard your business.
What are AI hallucinations, and what causes them?
Imagine your organization’s AI chatbot starts randomly telling high-profile customers that their account is locked due to “suspicious activity,” but your logs show no indication of any. This is a typical example of your AI hallucinating. This occurrence is more common with large language models (LLMs) — a subset of AI and the technology that most current AI chatbots and agents are built on.
LLMs specifically are prone to generating incorrect outputs because:
They are trained in next-word prediction tasks: LLMs fill in the next word based on patterns in the training data (likelihood of a token coming after the current one), with no fact-checking involved. This may lead to coherent-sounding responses that are actually incorrect.
They fill in the blanks even if they don't have the required data: LLMs are programmed to respond to prompts as best as they can. When the necessary information to reply is missing from the prompt or training data, they will fill in the blanks anyway, even if it means generating unfactual information.
They don’t always produce the same outputs: Because LLMs have a non-deterministic nature, they can give different answers to the same question. When this randomness is paired with the natural flow of language, the output sounds very natural and believable — even if it’s wrong.
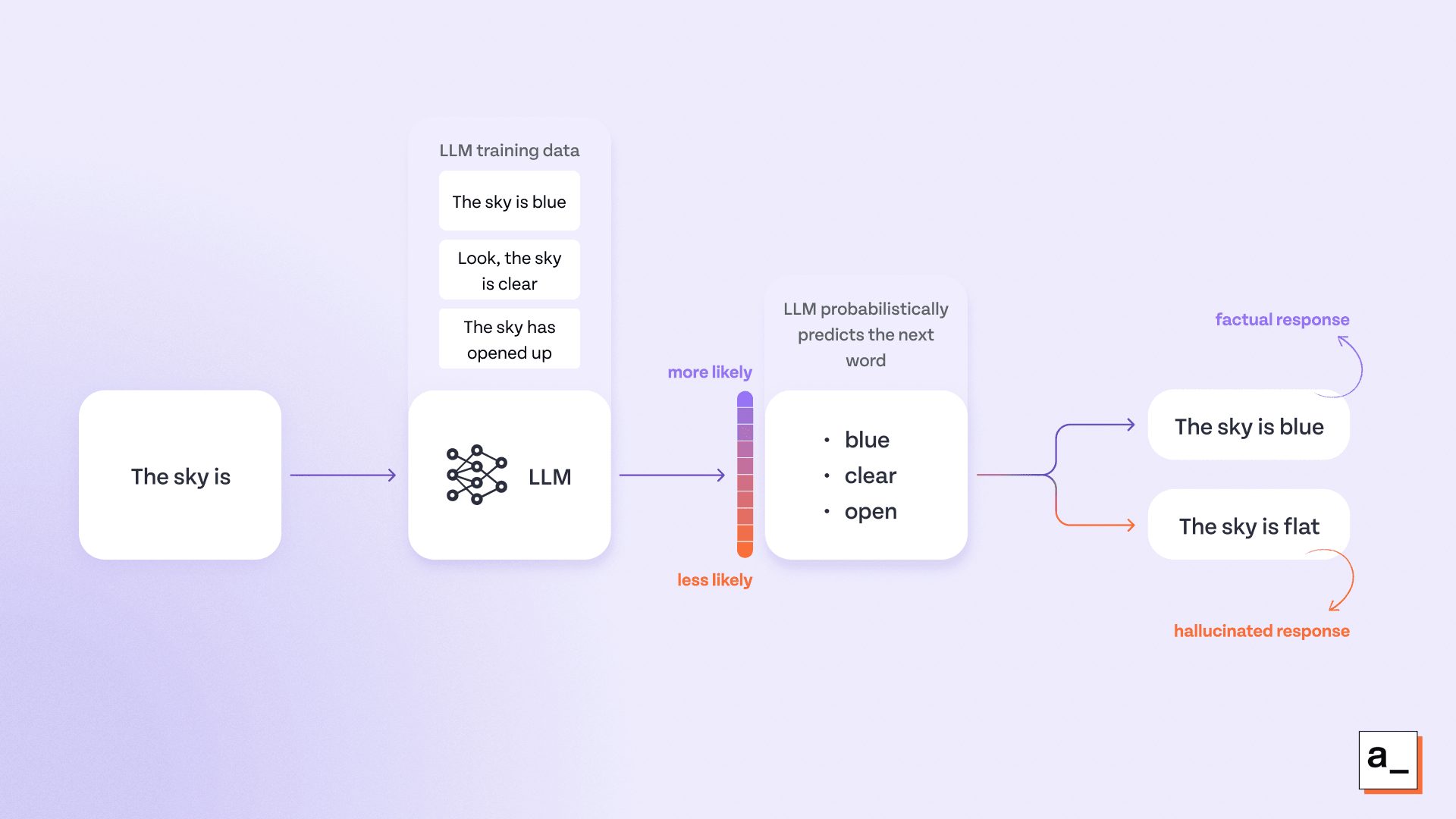
An LLM generating a factually incorrect response that wasn’t in the training data.
AI hallucinations have real-world impacts on businesses; for example, Google’s AI summaries have been known to give users bizarre suggestions like using rocks as a source of vitamins or adding glue to pizza to make the cheese stick. This may seem comical or relatively inconsequential, but it leads users to question Google’s reliability as a trusted source for accurate information, damaging its reputation.
Confidently generating false results is more dangerous than showing uncertainty. This presents a broader issue for businesses where it can have a domino effect on decision making. For example, hallucinated analysis or fabricated financial data, if not detected early in the pipeline, can exponentially get worse as it’s passed on to different departments. If left unchecked, these issues can also lead to legal ramifications.
It’s worth noting that hallucinations are not the same as responses generated from bad quality or maliciously injected inputs (such as data poisoning attacks). For example, if an LLM is trained on biased or incorrect data — like flat earth literature — and replies “no” to whether the earth is round, it’s not hallucinating; it’s just reflecting the (incorrect) information given in the training data.
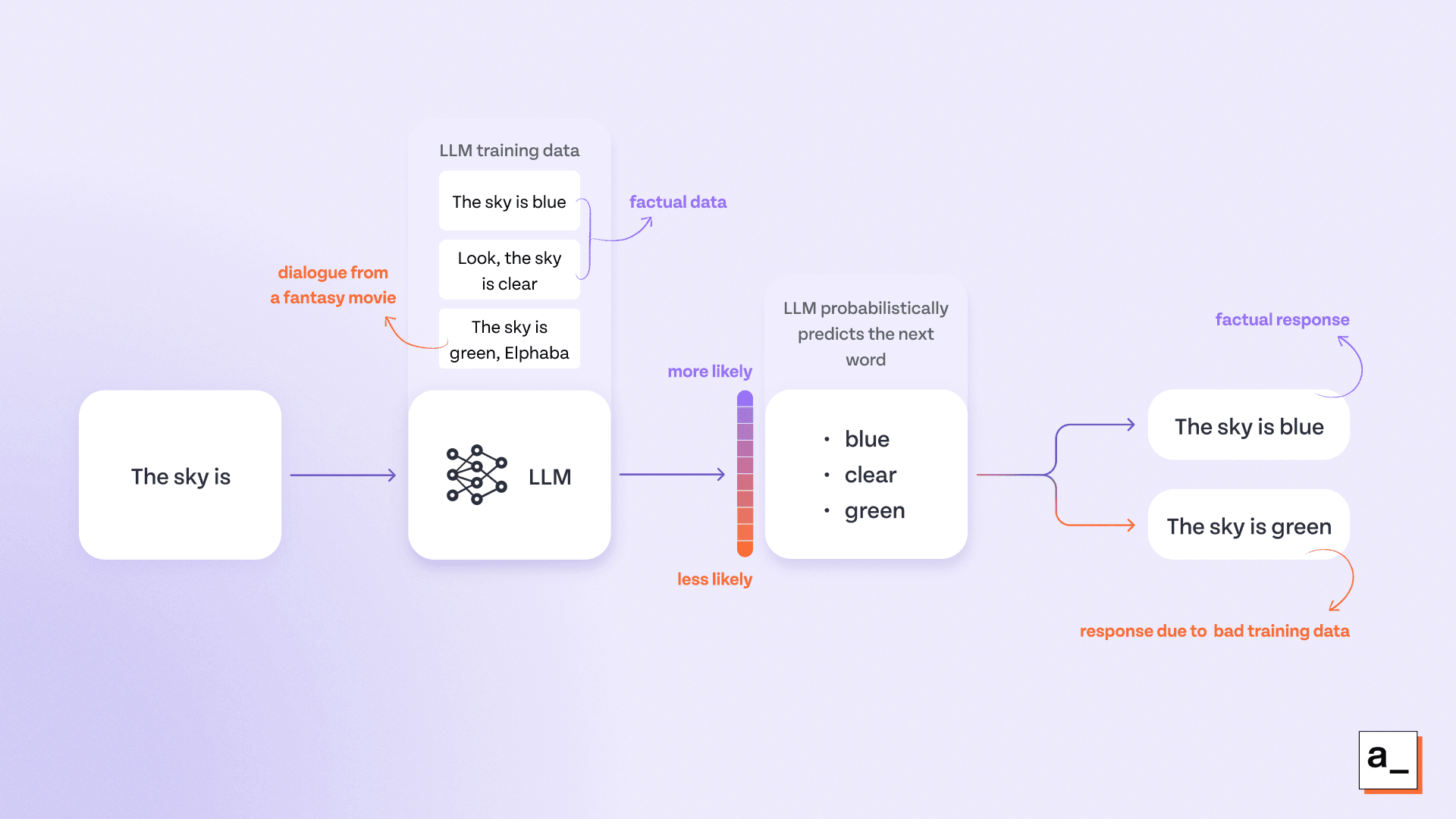
An LLM doesn’t hallucinate if it reflects its training data in the output.
How do you prevent LLM hallucinations?
While newer reasoning models like OpenAI’s o4 and Gemini’s Flash series may hallucinate less frequently, AI developers have yet to find a foolproof solution to this problem. Hallucinations are intertwined in how LLM-powered models function at a fundamental level.
That said, the benefits of AI to businesses' productivity, despite the risk of hallucinations, is clear and proven — and with the wide and rapid adoption of LLM powered AI, effective techniques like the following are evolving to combat hallucinations.
Guiding AI’s decision making
Techniques like prompt engineering and retrieval augmented generation (RAG), help you guide AIs decision making process without spending hours re-training models.
Prompt engineering
Prompt engineering is the process of iterating and optimizing how you prompt an LLM to get the best possible results. While simply adding more information may seem like an obvious solution, you need to ensure the prompt length is within the constraints of the LLM’s context window.
Smart prompting can steer the LLM to generate more accurate results and minimize hallucinations. Two approaches that have emerged as an extension of prompt engineering are:
Few-shot prompting provides the LLM with some examples of how you want it to perform to make the outputs more accurate. Simply adding a few examples to the prompt improves accuracy and reduces the chances of hallucination. This specifically enhances responses for tasks that need domain-specific knowledge or the output formatted in a specific structure.
Chain-of-thought Reasoning (CoT) helps the LLM break down its decision-making process, making the logic transparent. This approach does notably well on complex reasoning tasks. You can easily set up CoT by editing the system prompt to ask the LLM for a plan of how to get the answer and how the LLM synthesized the information to get to the answer.

Unlike regular prompting, CoT encourages the model to explain its thought process.
Another key aspect of prompt engineering is that it lets you include guardrails — system instructions to LLM agents to constrain and define their behavior — to make less confident outputs more visible. In terms of reducing hallucinations, you could give the LLM an escape hatch it can take instead of generating a false output, such as “Reply with ‘I’m not sure’ if you don’t know the answer.”
Retrieval-augmented generation
Retrieval-augmented generation (RAG) uses verified external data (for example, information from your CRM, knowledge base, or other documents) and optionally limits the LLM to using only that data. This makes sure the information being used to generate responses is factually correct.
Some variants of RAG include:
Vector RAG: Uses semantic similarity to find relevant information quickly.
Graph RAG: Uses knowledge graphs to map concepts together and ensure the facts make logical sense, making it a better choice for reducing hallucination.
Hybrid RAG: Combines Graph RAG and Vector RAG, giving factual accuracy along with relevant results with the help of structured and unstructured data.
Another technique that has been gaining a lot of traction lately is LLM-as-a-judge, which is using LLMs to judge the output of other LLMs. By essentially following a peer review process, you can have secondary LLMs evaluate and flag potential errors in your primary LLM agent’s responses.
Directly enhancing AI models
If you’re looking for more control over your AI systems, consider directly enhancing them with techniques like sampling, fine tuning and human intervention.
Adjusting hyperparameters: temperature and sampling
Temperature is a parameter that decides how random or deterministic a model’s responses are: lower values (~0.3) tell the model to generate safer, more likely responses, and higher values indicate more creative and diverse outputs. Controlling a model’s temperature makes the output more predictable.
Using sampling techniques like nucleus sampling also helps narrow down the model’s choices for the next probable word during token prediction. Also known as top-p sampling, nucleus sampling reduces the likelihood of the model selecting unlikely next words by only considering words where the cumulative probability is above a threshold (p).
These simple changes reduce the model’s creativity, but they also bring down hallucinations.
Human-in-the-loop validation
Human-in-the-loop validation is a relatively simple approach where human experts catch incorrect AI responses and remove them before they reach users.
HITL workflows typically involve a user interface (dashboard) where human experts can review AI-generated responses that have been flagged before they are delivered to the user. Annotation tools help correct inaccurate outputs, which are fed back into model training through feedback loops. This continuously improves an AI model’s reliability and accuracy.
Using experts in AI pipelines to manually catch errors can be expensive, but it’s the most foolproof method to correct hallucinations. If you’re working on a high-priority task, HITL is still the gold standard for providing fact-checked responses to customers.
Fine-tuning and alignment
You can fine-tune LLMs on high-quality, verified data so the responses are more likely to be factually accurate and aligned to a specific use case that general-purpose LLMs might not be trained to handle. Two commonly used techniques are:
Supervised fine-tuning: Retrains models on carefully designed and curated high-quality datasets.
Reinforcement learning from human feedback (RLHF): Extends HITL by using human inputs to refine the model's performance, retraining it on the corrected data points.
These techniques have a very high time and cost requirement and are best suited for self-hosted models instead of public LLM APIs; however, they can bring the frequency of hallucinations down dramatically.
Ensemble and voting strategies

A voting based technique where the majority vote of different models is selected.
Why should you rely on a single model when you can have a whole team? This is the idea behind ensemble strategies: by combining the output from different models, it’s unlikely that all of them will hallucinate. Doing multiple runs (which can be automated) or using specialized “adversarial” models is a reliable way to catch wrong answers.
Adversarial models have been trained on hallucinated data and induced with errors to function like a hallucinated model. By mimicking how a hallucinated model would behave, comparing results of the standard model outputs with an adversarial tuned one can catch fabricated answers.
Voting strategies bring this all together: when differently configured models or runs produce different outputs, a majority vote is used to select the most reliable answer.
Building more dependable AI solutions
As new businesses are adopting AI solutions, it doesn't just mean rushing towards larger, powerful models — it’s also about choosing a smart workflow and ensuring quality control. Early mitigation and detection of hallucinations becomes a crucial factor in building trust. If you’ve made it to this point, you’re clearly passionate about creating more dependable AI solutions. We’ve been busy cooking up something new for developers ready to build and ship AI that actually does what you expect. Join our waitlist to see what’s coming next.
FAQ
Q: What is LLM hallucination?
A: LLM hallucination is when AI generates plausible-sounding responses that are factually incorrect.
Q: Why do LLMs hallucinate?
A: LLMs generate responses based on patterns in their training data. However, when the required data is missing, they fill in the blanks and provide factually incorrect responses.
Q: What are some steps I can take to de-hallucinate LLMs in my organization?
A: Reduce LLM hallucinations by using techniques like retrieval-augmented generation (RAG), human-in-the-loop (HITL), and prompt engineering.


